
Every app you open, website you visit, or product you use generates data. From clicks and searches to purchases and preferences, these signals help companies understand behavior, improve products, and fuel digital experiences. This process, known broadly as data collection, sits at the core of today’s internet economy.
But while data collection powers convenience and innovation, it also raises an important question: who controls the data being collected?
Understanding how data collection works is the first step toward taking ownership of the value you create.
What Is Data Collection?
At its simplest, data collection is the process of gathering information for analysis, decision-making, or record-keeping. In digital environments, this often means capturing user interactions such as what you click, how long you stay on a page, or what you buy and then storing that information in systems that can analyze it later.
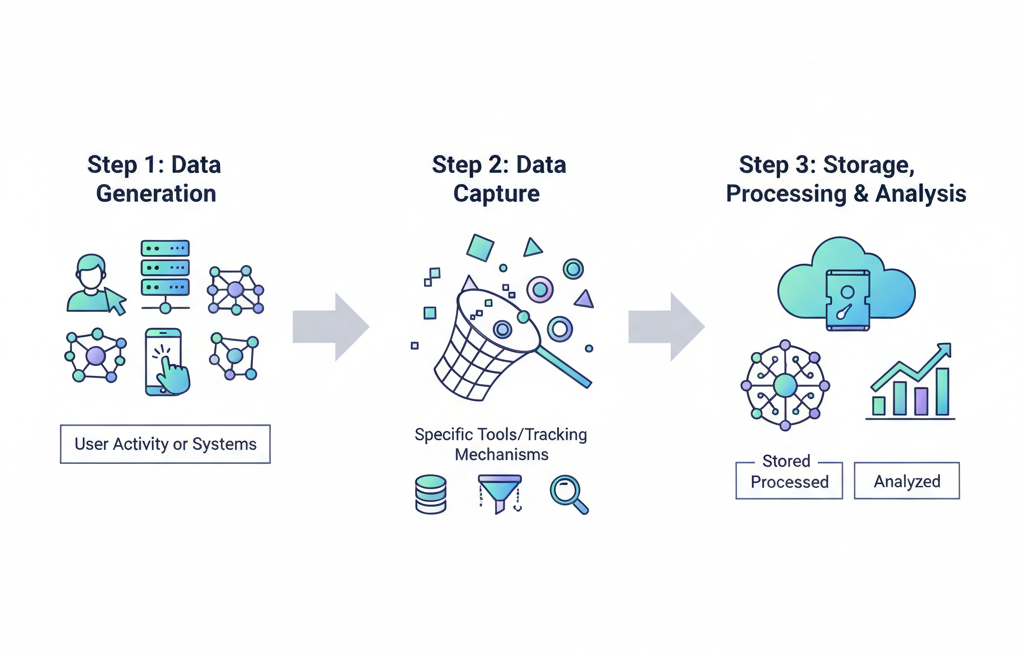
The data collection process typically follows a few basic steps:
- Data is generated through user activity or systems
- It’s captured using specific tools or tracking mechanisms
- The information is stored, processed, and analyzed
There are many types of data collection, ranging from direct input (like filling out a form) to automated tracking (like background app usage). Data collection matters because it enables personalization, performance measurement, fraud detection, and product improvement across nearly every digital platform.
Importantly, data collection itself isn’t inherently bad. In many cases, it makes apps more useful and services more efficient.
The real issue is control, who decides how the data is used, who benefits from it, and whether individuals have any meaningful say in the process.
Common Data Collection Methods Used by Companies
Modern companies rely on a wide range of data collection methods to understand users and markets. These data gathering methods have evolved alongside digital products, becoming more automated, continuous, and granular over time.
Some of the most common data collection techniques include:
- First-party data collection: Data collected directly from users through owned channels like websites, apps, or customer accounts.
- Examples include account details, purchase history, and in-app behavior.
- Third-party data collection: Data gathered by external providers and shared or sold to other companies, often aggregated across many platforms.
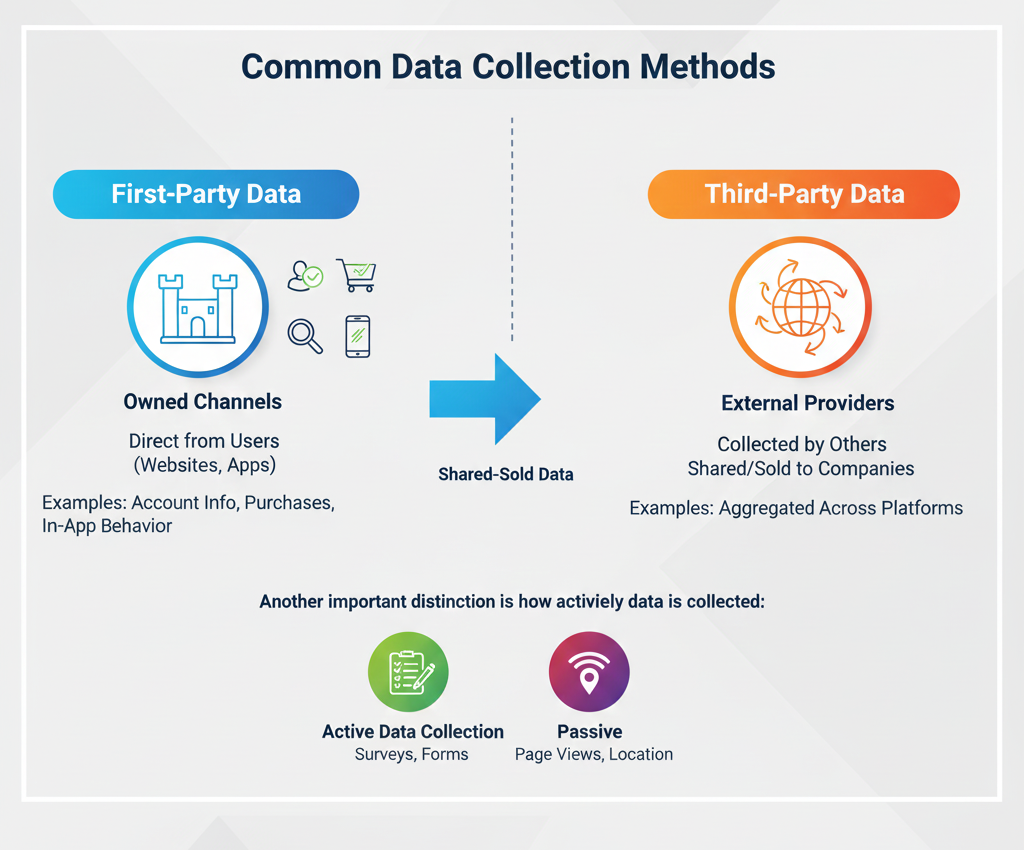
Another important distinction is how actively data is collected:
- Active data collection occurs when users knowingly provide information, such as completing surveys or submitting forms.
- Passive data collection happens in the background, such as tracking page views, location data, or device characteristics.
As products have become more connected and data-driven, these methods have expanded, often operating continuously and at massive scale.
Types of Data Collection You Encounter Every Day
Many types of data collection are so common that they fade into the background of daily life. Some familiar examples include:
- App usage tracking: Monitoring how often you open an app, which features you use, and how long sessions last.
- Forms and surveys: Collecting structured responses through sign-up forms, feedback surveys, or questionnaires.
- Cookies and device data: Using browser cookies, IP addresses, and device identifiers to recognize returning users or track sessions.
- Transaction and behavioral data: Recording purchases, subscriptions, clicks, and navigation patterns.

Much of this information is quantitative data, numbers and measurable attributes that can be easily analyzed at scale. While these data points may seem small individually, together they form detailed behavioral profiles.
How Companies Use Your Data After It’s Collected
Once information is collected, it rarely stays raw. Companies transform individual data points into a structured dataset that can be analyzed and reused across teams.
At this stage, analytics tools help identify patterns in behavior, while machine learning systems rely on labeled data, a process known as data annotation, to train and improve algorithms over time.
This behind-the-scenes processing is what enables familiar experiences like personalized recommendations, targeted advertising, smarter product decisions, and AI-powered automation.
Understanding how companies use your data reveals why it’s so valuable. Your interactions don’t just improve a single app or service, they often contribute to broader insights, predictive models, and long-term revenue streams.
In most cases, however, users never see or share in the value their data helps create.
Behind the Scenes: Data Integrity, Normalization, and Governance
For data to be useful, it has to be trustworthy and well-organized. Data integrity refers to the accuracy, consistency, and reliability of data over time. Poor integrity often caused by duplicates, errors, or manipulation can undermine analysis and decision-making.
Data normalization helps address these issues by standardizing how information is stored and structured, making large datasets easier to combine and analyze. Without normalization, comparing data across systems becomes difficult or misleading.
Overseeing all of this is data governance: the policies and processes that determine who can access data, how it can be used, and under what conditions. Governance structures effectively decide where power lies in the data ecosystem.
The Problem With Traditional Data Ownership Models
Despite generating the data, users rarely own it in traditional systems. Companies collect, store, and monetize information with limited transparency, leaving individuals with little insight into how their data is used.
This imbalance creates several challenges:

- Users generate value but rarely benefit financially
- Opt-out mechanisms are often unclear or limited
- Data privacy risks increase as data is shared or centralized
- Individuals lack real data control once information is collected
These issues have fueled growing concerns around data ownership and prompted calls for more user-centric approaches.
For broader context on consumer data practices, organizations like the Federal Trade Commission and OECD have published extensive guidance on data privacy and governance.
How Vana Enables User-Owned and Decentralized Data
Vana offers an alternative to traditional models by enabling user owned data through decentralized infrastructure. Instead of data being siloed inside corporate platforms, users can contribute their data to collective systems they help govern.
At the heart of this approach are DataDAOs, which allow communities to pool data for shared benefit while maintaining individual consent. You can learn more in Vana’s deep dive on DataDAOs and collective ownership.
Vana’s broader mission, outlined in Vana’s vision for user-owned data, is to shift power back to individuals. Through decentralized data systems, users decide:
- What data to share
- How it can be used
- Who benefits from its use
For a technical overview, see how Vana works, which explains the underlying architecture that makes decentralized data possible without sacrificing privacy.
Data Portability and Control: Putting Ownership Into Action
True ownership requires more than consent, it requires mobility. Data portability means being able to move your data between platforms, contribute it to research, or monetize it on your own terms.
Portability is essential because it prevents lock-in and enables competition. When users can take their data with them, they gain leverage and choice.
Vana supports this through tools and standards designed for safe, user-directed sharing. For a deeper look, explore Vana’s documentation on data portability, which explains how users can securely move and reuse their data while preserving privacy.
Why the Future of Data Collection Is User-First
The future of data collection is moving away from extractive models toward participatory ones. Instead of data being something taken from users, it becomes something they actively manage and benefit from.
User-first data systems offer clear advantages:
- Individuals gain transparency, control, and potential economic upside
- Researchers access higher-quality, consented datasets
- Companies build trust and sustainable data practices
Vana’s roadmap, outlined in the Vana whitepaper, illustrates how decentralized data ecosystems can support innovation without compromising individual rights.
As data continues to shape the digital world, understanding data collection methods and rethinking ownership will be critical.
The question isn’t whether data will be collected, it’s whether users will finally have a meaningful role in how it’s used.

